2020-09-20 周报
1. 本周主题
主题:Recommendation based on translation vector
论文:
- 《Translating embeddings for modeling multi-relational data》,出处:2013 NIPS,引用次数:2418
- 《Translation-based Recommendation》,出处:2017 ACM,引用次数:150
- 《Translation-based Factorization Machines for Sequential Recommendation 》,出处:2018 ACM,引用次数:31
- 《Adaptive Hierarchical Translation-based Sequential Recommendation》,出处:2020 WWW,引用次数:5
2. 论文介绍
2.1 Translating embeddings for modeling multi-relational data
2.1.1 Motivation
这篇论文的motivation来源:
- 作者认为很多KBs的表示方法都含有层次关系,类似一个树结构,每一个节点的Embedding可以用这个节点下面的子树和叶节点表示,那么节点和节点的关系,同样可以表示为实体共同的父节点;
- 来源于 Word-Embedding 的思想, 使用大量文本训练利用词的顺序训练Embedding向量;
这两个motivation合起来理解就是通过分布式稠密向量来表示实体和关系, 更好的描述他们的流转。如果把一个关系表示为一条边 $(h,l,t)$, $t$ 为 tail,$l$ 表示关系,$h$ 表示head,那么 $h$ 的Embedding 加上 $l$ 的Embedding 就应该在数值上接近 $t$ ,这个模型整体的可训练参数就是 $h,l,t$ 的Embedding矩阵;
2.1.2 具体算法
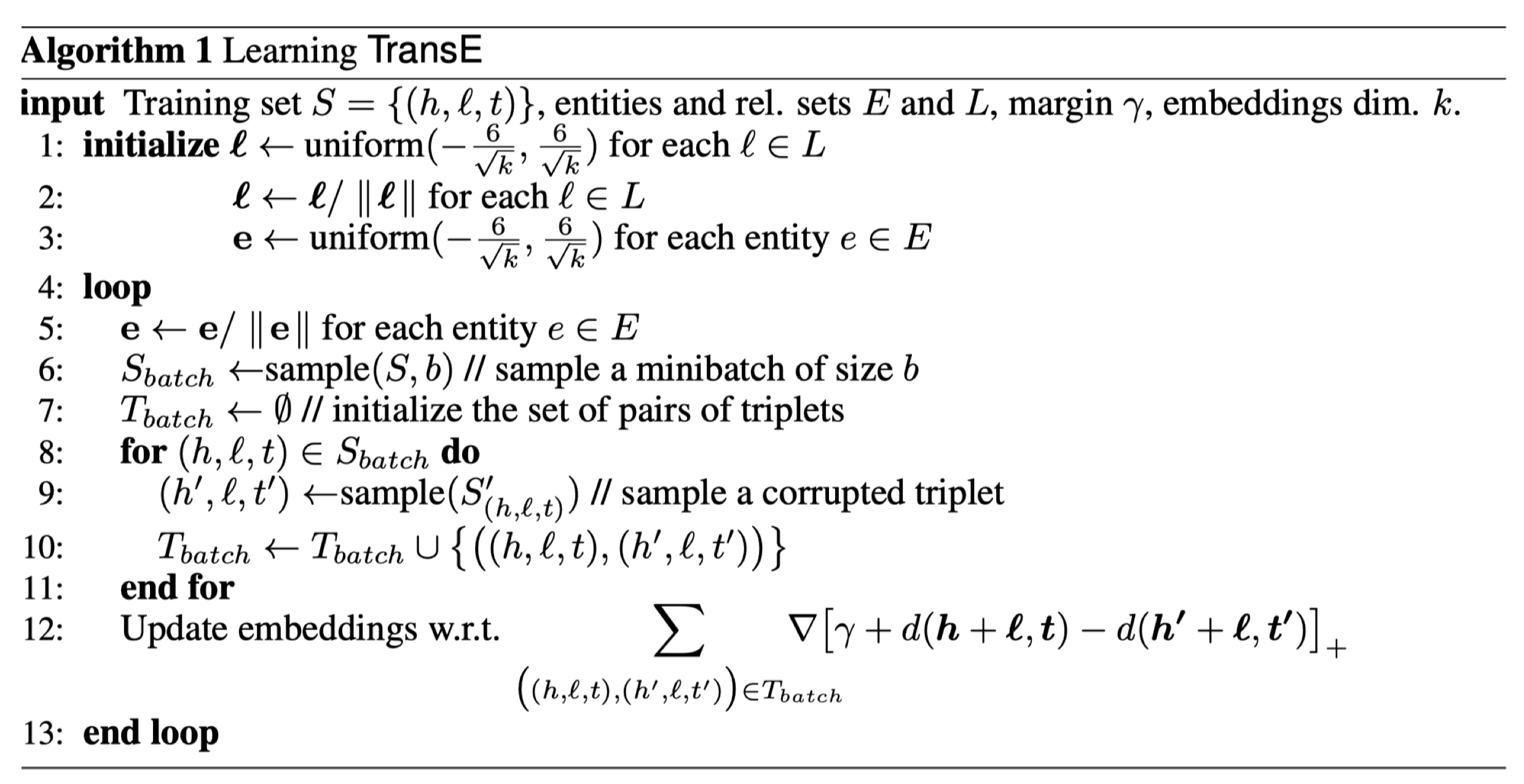
算法具体解释:
- 使用uniform distribution 初始化关系 $l$ 的embedding向量;
- 对关系 $l$ 的embedding 进行标准化;
- 初始化实体 $e$ 的 Embedding;
循环:
- 每一次循环迭代后要对 $e$ 的embedding 标准化;
- 在 $S$ 中随机抽取 $b$ 个对关系作为一个循环迭代的batch;
- 初始化一个空的关系集 $T_{batch}$ ;
- 每个batch中的关系进行循环;
- 对于每个关系的实体进行打乱产生一个负样本;
- 把真实关系和生成的乱序关系都加入到关系集合 $T_{batch}$ 中;
结束循环
- 使用损失函数的梯度进行Embedding 参数的更新。
这个算法使用的损失函数是一个 energy-based 损失, 具体如下:
$[x]_+$ 表示只考虑 $x$ 正数的部分;
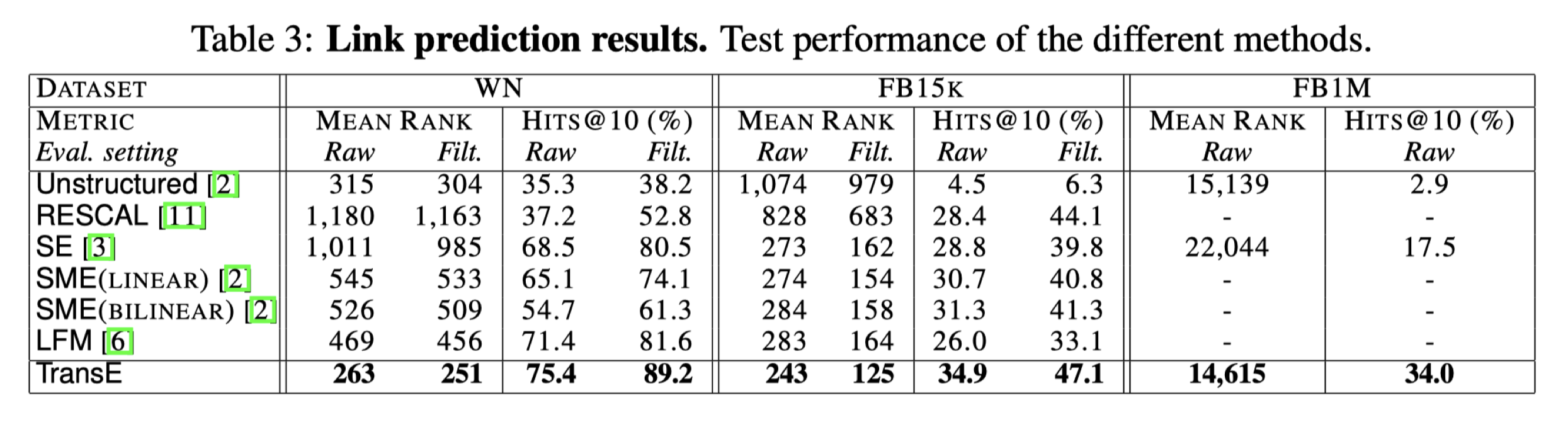
2.1.3 实验
2.1.4 模型缺陷
这个模型只能处理一对一的关系,不适合一对多/多对一关系,例如,有两个知识,(skytree, location, tokyo)和(gundam, location, tokyo)。经过训练,“sky tree”实体向量将非常接近“gundam”实体向量。但实际上它们没有这样的相似性;
2.2 Translation-based Recommendation
2.2.1 Motivation
这篇论文的 motivation 来源:
- 来自于对论文 《Translating embeddings for modeling multi-relational data》方法的引荐,将三元组关系建模方式引入推荐系统中;
- 在欧几里得空间中利用三角不等式的关系进行向量的规范性限制;
2.2.2 具体算法

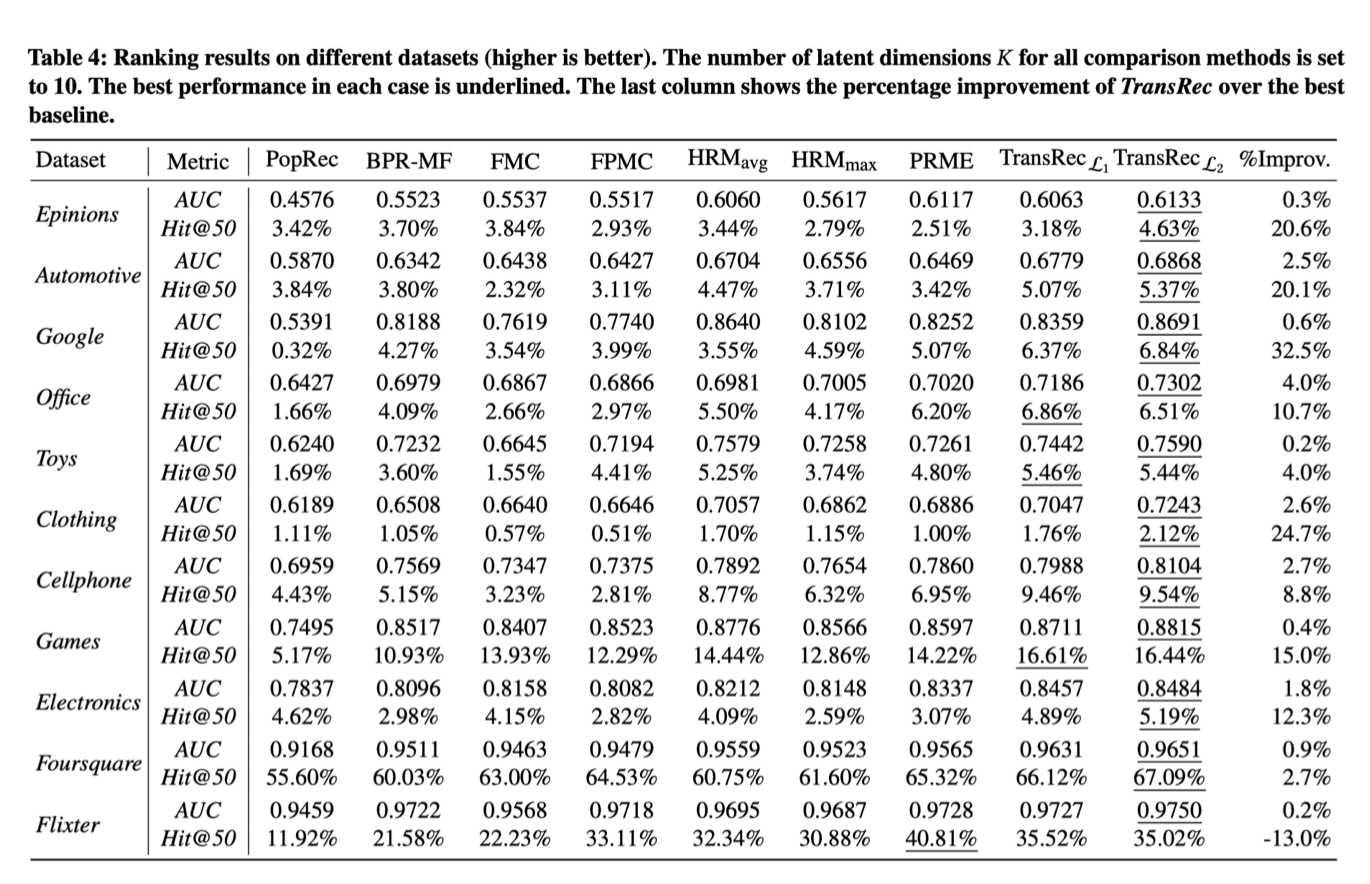
2.2.3 实验
2.2.4 模型缺陷
- user与item的交互是向量级别的简单相加,可能不会捕获到更强的交互;
- 未引入上下文信息;
2.3 Translation-based Factorization Machines for Sequential Recommendation
2.3.1 Motivation
- 来自于对论文 《Translation-based Recommendation》方法的引荐,将基于三角不等式的向量建模方法引入到因子分解机中;
- 引入平方欧氏距离来替代向量内积进行特征衡量;
2.3.2 具体算法
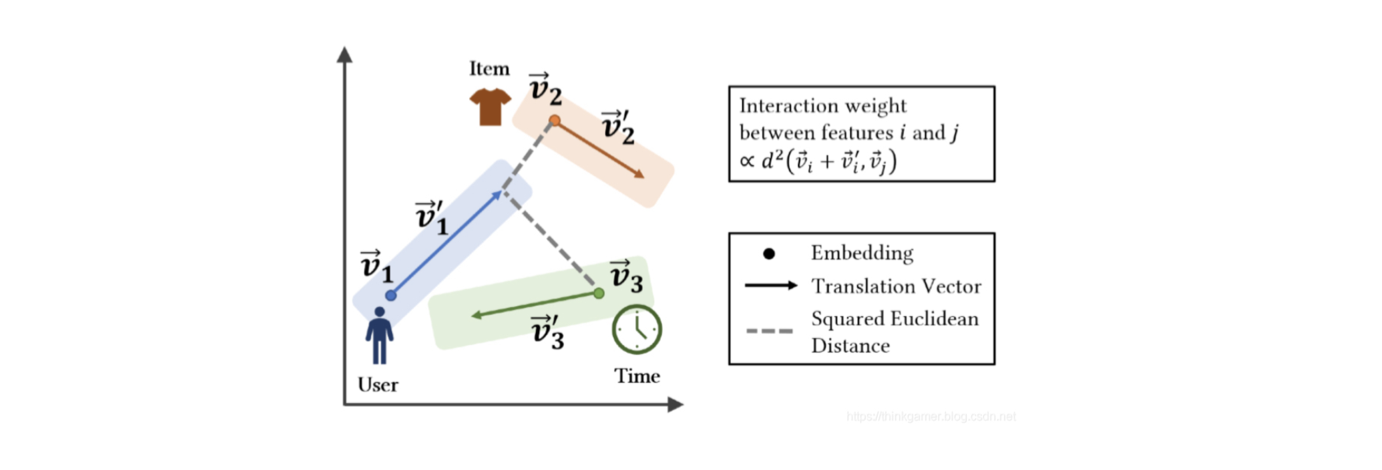
TransFM是对所有观察到的行为之间可能的交互进行建模,对于每一个特征i,模型学习到两部分:一个低维的embedding向量$\overrightarrow{v_i}$和 一个 translation vector $ \overrightarrow{v_i’}$ ;特征之间的交互强度使用平方欧几里德距离来进行计算,在上图中显示了user,item,time的embedding特征和translation vector,交互行为之间的权重由起始点和结束点之间的平方欧几里德距离进行计算。与FM一样,TransFM 可以在参数和特征纬度的线性时间内进行计算,从而有效的实现大规模数据集的计算,模型的最终预测计算公式为:
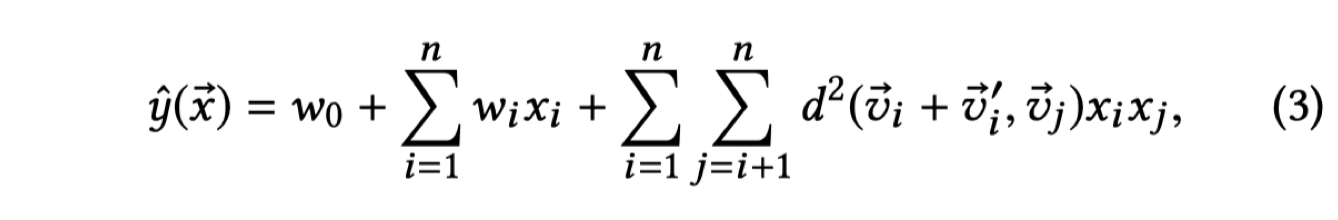
2.3.3 实验
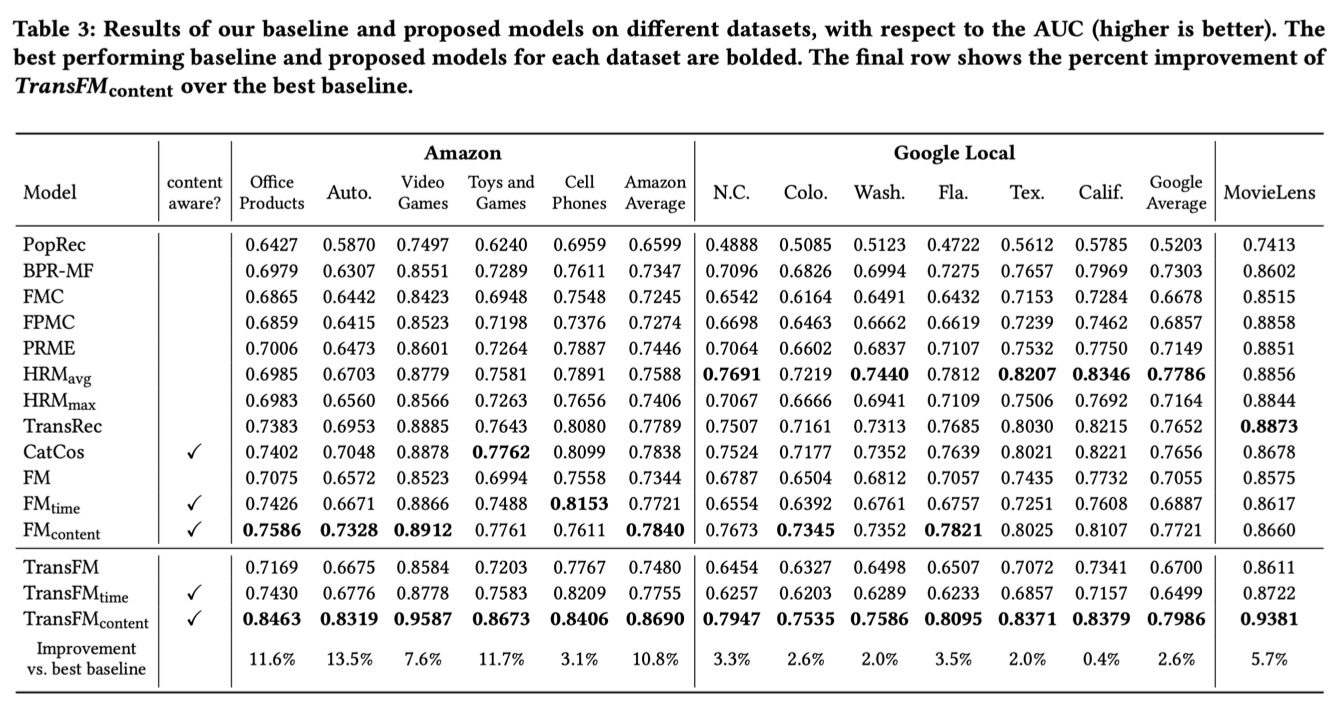
2.3.4 模型缺陷
- 模型在特征矩阵增大的情况下,计算复杂度与时间复杂度会线性增加;
- 没有引入额外的属性与信息,另一方面忽略了商品与用户之间的高阶连续性;
2.4 Adaptive Hierarchical Translation-based Sequential Recommendation(WWW2020)
2.4.1 Motivation
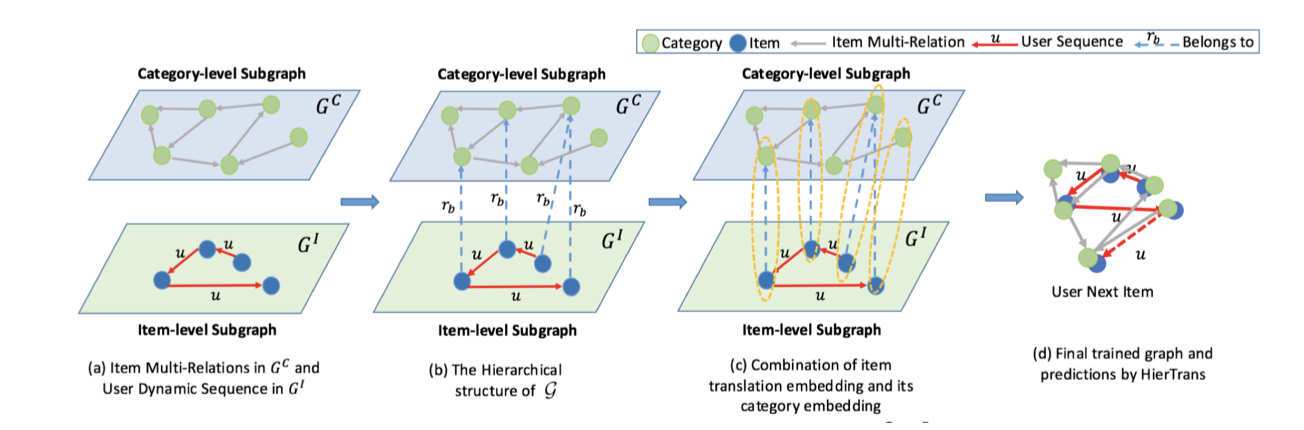
- 引入多层次时序图,也即 item 时序图和 category 图;
- 将 item 的 category 引入一个新的图中,并构建与 item 图的联系进以扩充 item 的embedding 信息;
- item 图中,在item 与 item 结点之间引入动态 user 的边关系,将原来的静态边更改为动态边,保证动态用户偏好性可以被模型学习到;
- translation vector 基于用户的动态偏好性(时间)、用户序列、用户的历史交互项目会适应性的进行改变;
2.4.2 具体算法
2.4.2.1 前言
变量声明:
- 用户集 $U$
- 商品集 $I$
- 商品的类别集 $C$
- 用户 $u$ 与商品交互序列 $S^u = {s^u1,…s{|s_u|}^u}$
模型输入与输出:
- 输入:给定一个用户 $u$ 与商品交互序列 $S^u = {s^u1,…s{|s_u|}^u}$
- 输出:用户 u 的下一个可能购买的商品
2.4.2.2 多层次时序图
这里主要构建两个多层次时序图:
- $G^C$:捕获item间基于category层次的多种类别关系;
- $G^I$:捕获基于item层次的用户动态序列;
首先构建 $G^c$,$G^C$ 的结点来源于 item 的 category 集合,另外,将 item 关系扩展到 category 层次,需要满足以下的规则:
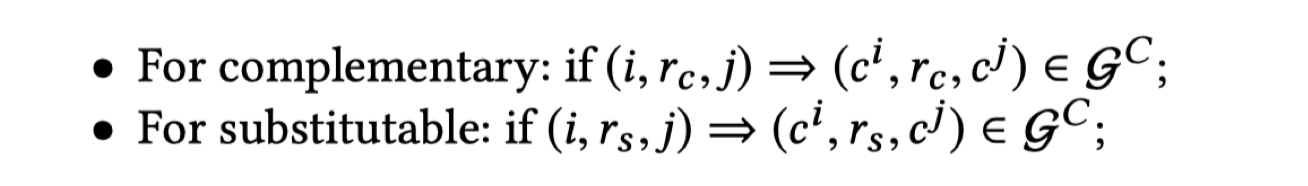
注:
- $r_c$ :代表基于补充的关联关系;
- $r_s$:代表基于替换的关联关系;
补充性规则:如果 item i 补充 item j,那么 item i 的 category 补充 item j 的 category;
替换性规则:如果 item i 替换 item j,那么 item i 的 category 替换 item j 的 category;
基于以上规则这里论文给出的例子解释是:
- 针对替换性规则,例如 ipad2 需要被更新为ipad3,这两个ipad是属于同一 category 的物品,所以 ipad2 处于 category 层的关系可以被考虑为是 ipad3 处于category 层的关系,也即如果用户买了 ipad 3,那么 ipad2 也可以作为一个推荐中间项被加入到该用户;
- 针对补充性规则,例如 laptop 和 mouse 是互补的,通过互补关系可以推断出 laptop 与 mouse 的 category 是高度相关的,那么,买了 laptop 之后很自然的会被推荐 mouse;
其次构建 $G_I$,$G_I$ 的结点来源于 item ,但是 $G_I$ 中的边关系来源于用户与商品的交互序列 $S^u$,同时需要满足以下规则:
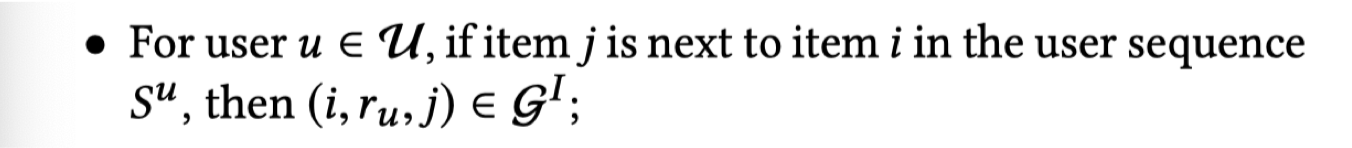
注:
- $r_u$ 代表以用户为链接的关联关系;
最后,把图 $G^C$ 与图 $G^I$ 链接起来,其链接规则为:

注:
- $r_b$ 代表归属关系;
2.4.2.3 基于多层次模型的推荐
在完成图的构建之后,就可以针对具体的特征进行建模了,首先,论文给出了一个进行预测的公式:
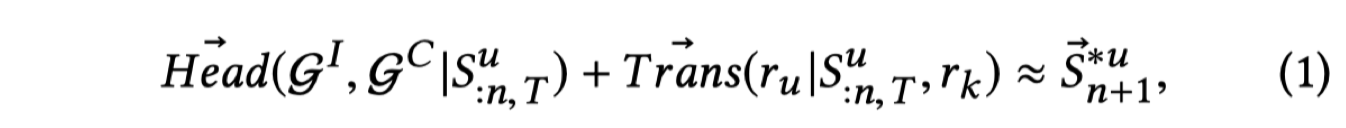
注:
- 公式第一项:一个条件概率,也即基于用户 $u$ 的 $T$ 个交互项构建图 $G^C$ 与图 $G^I$ 的值,用于捕获图 $G^I$ 中的用户个人动态偏好性与图 $G^I$ 中item 的多重关系;
- 公式第二项:translation vetor,是一个条件概率,基于基于用户 $u$ 的 $T$ 个交互项和关系 $r_k$ 来找到对应关系 $r_u$ 的值,用于衡量用户的动态迁移过程,这里与传统的 translation vector不同,这里的 translation vector可以根据用户的历史交互记录、用户序列中的关系 $r_k$、用户的偏好性进行动态建模;
- 公式第三项:用户 $u$ 下一个购买的商品序列;
公式(1)的各项计算过程:
公式第一项:
- 在 $G^C$ 中利用三元组 $(c^i,r_k,c^j)$ 基于欧几里得空间的三角不等式关系,已知 $c^i 与 r_k$ 推出 $c^j$,这里计算公式为(公式2):$c^i + r_k \approx c^j$;
- 在 $G^I$中引入上一步得到的 category 关系扩充 item i 的 embedding 信息,这里计算公式为(公式3):$i^* \approx c^i + i$,这里 $i$ 代表 item embedding,$c^i$ 代表 item i 的 category embedding;
公式第二项:
构建基于用户偏好性与 item 关系的translation vector:
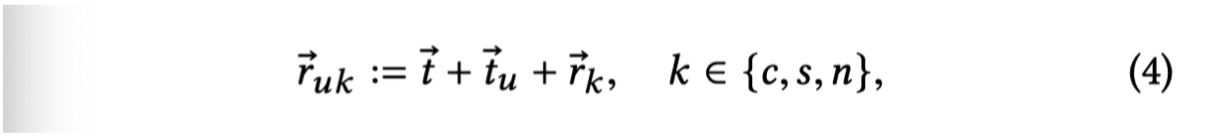
这里 $t$ 代表所有用户的全局转移信息,用以增加泛化能力,这个做法在文章《Translation-based Recommendation》已经被使用过;$t_u$ 代表用户个人偏好性转移;$r_k$ 代表不同的 item 关系 embedding;
最后利用注意力机制捕获用户 $u$ 可能选择的下一个 item:
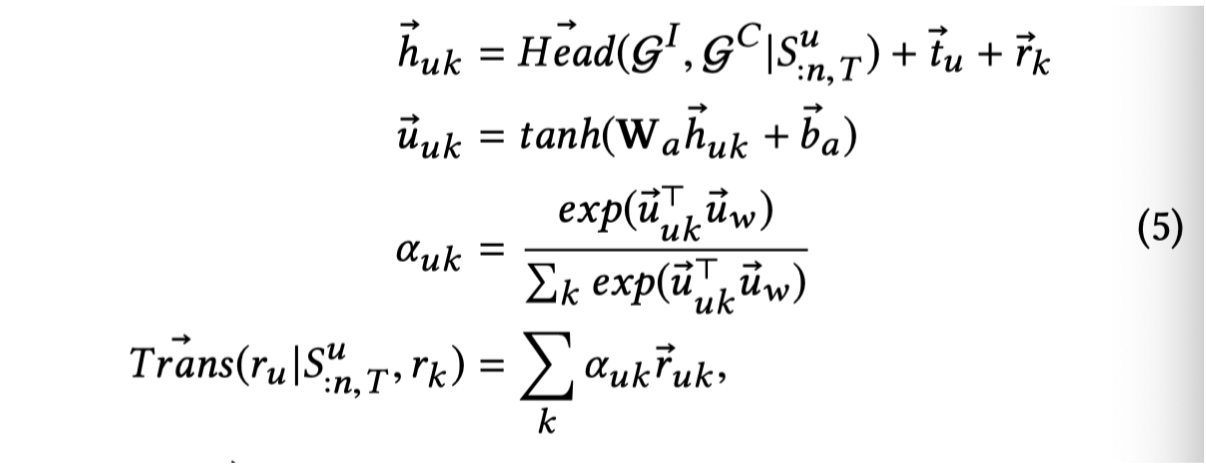
基于公式(5),由于用户的 translation vector是根据用户先前的交互项目、用户的关系模式(Head()项)、用户偏好性($t_u$)、用户的偏好项目关系($r_k$),所以可以说是 adaptive 的;
2.4.3 实验
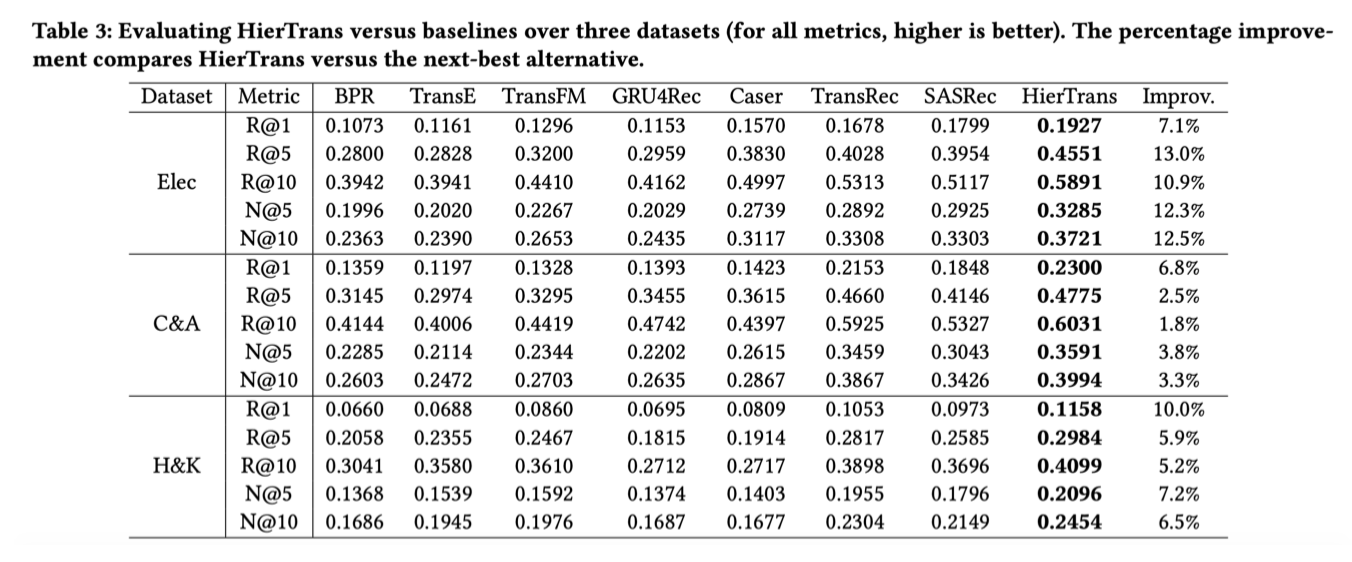
- 评估机制常见;
- 数据集常见;
- 代码:未上传
2.4.4 个人总结
- 本文提出的模型主要是依靠欧几里得空间的三角不等式规则进行计算,如果向量之间不满足三角不等式的关系,或者不适用于欧几里得空间,那么无法确定模型的好坏;
- 本文引入了大量的动态信息,信息传递过程中是否会存在信息缺失问题;
- 在计算 translation vector过程中存在使用注意力机制的过程,是否会导致计算速度过慢,以及非公平性;
- 本文可以值得借鉴的创新点:引入动态信息(摆脱传统的静态信息)与辅助图(扩充可利用的推荐信息);